
Irregular shadow mapping
In the following I use the word "pixel" rather loosely for a wider audience, and in its place should be any of pixel, texel, fragment or "grid cell."

Demo of low-res shadow map. Note the blocky shadow.
When it comes to shadow algorithms, the lure of wholly dynamic scenes makes most settle for some extension of shadow mapping. The algorithm involves rendering the scene (specifically, a depth map) from the point of view of each light, allowing you to compare the distance between each point you can see to the light source. If the distance in the depth map is smaller than that of the point's distance to the light, it means something else is closer, hence there is a shadow.
At its core, the algorithm is extremely simple and intuitive, and it's no surprise it's the common choice, but the generic nature of an algorithm is a double-edged sword, and always leads to nasty drawbacks. Most points in a scene are so far away from the light that the resolution of the depth map gives shadows a pixelated look. The size of the render from the light's view is also bounded in size, so whatever doesn't fit cannot affect the scene.
Most rendering engines "fix" said issues, but in ways that are nothing but hacks upon hacks that simply hide the mess within.
There's another method for shadows since at least 2004, but as hardware then was incapable of the technique, it was forgotten. The technique is Irregular Shadow Mapping. A key paper can be found here, but I intend to expose it in a more readable form in this article.
The original shadow mapping algorithm prioritizes the light's view, which means a single pixel in the shadow map can apply to tens, maybe hundreds, of pixels in our main render, causing the blocky look. This is the main problem behind it. As we should prioritize the main view, we should do the reverse: map each pixel in the main view to a pixel in the shadow map. Thus, this algorithm begins by rendering from the main view first. This should immediately raise a few questions. An image stores exactly one value in each of its pixels, so how does one insert potentially hundreds of points into one pixel of the shadow map?
Our novel shadow map, which I shall call a shadow multimap for clarity, is nothing but a two-dimensional buffer. Instead, let us say it holds indices to a second buffer. This second buffer is an array of elements, where each element contains another index to the next corresponding item. These two buffers unite to form a giant spaghetti of linked lists.
Per-pixel linked lists themselves are not new. They're one of the main ways of implementing order-independent transparency. The ability to map one to many pixels opens doors to much other advanced graphics techniques, but it is one of multiple things that made irregular shadowing impractical back in 2004.
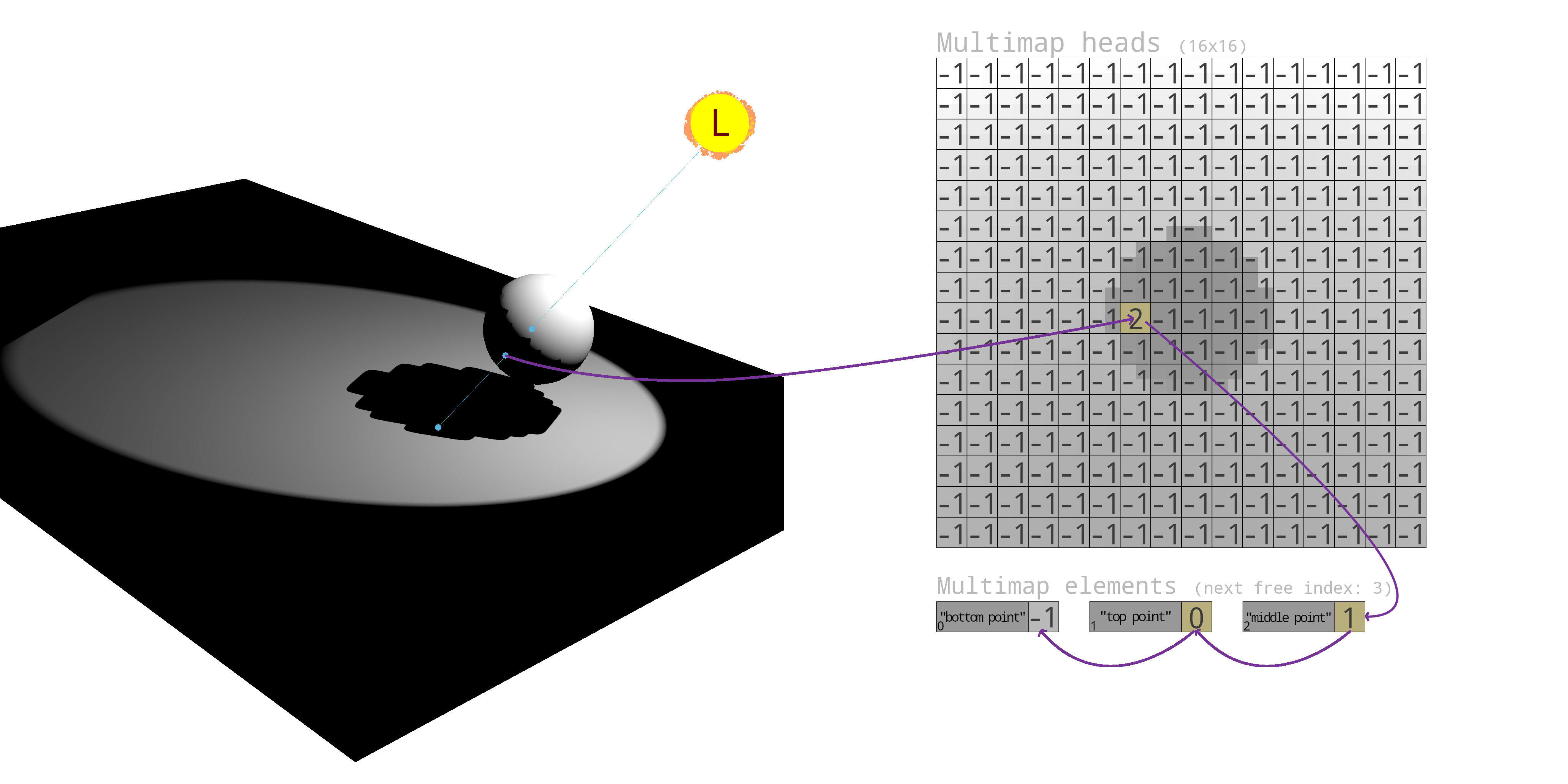
And it was so. As an example, I've marked in blue three points in the scene which map to the same pixel in the multimap, and visualize how a linked list is formed with the two buffers (-1 signifies the end of a linked list). The background in the multimap is purely for the reader, and does not indicate what is actually stored.
We need a fragment shader that will be sending thousands of threads to fill this buffer with linked lists, so it is imperative to avoid race conditions, so as to make sure we don't boil our spaghetti into one long noodle. Additionally, our elements buffer will reach large sizes, so we shall need shader storage buffers. There must be a depth pre-pass before this so that at most one fragment per pixel is written to the linked list, and this is also why the shader enables early fragment testing.
// Fixed resolution for simplicity
#define MAX_POINTS (1500000)
layout(early_fragment_tests) in;
layout(r32ui, binding = 0) uniform uimage2D u_multimap;
layout(std430, binding = 0) buffer Elements {
uint ElNextFree;
// I've went for a struct of arrays (SoA) approach because otherwise there's horrible padding overhead
// The indices to the next items in the respective linked list
uint ElNexts[MAX_POINTS];
// Points projected in light-space
vec3 ElPoints[MAX_POINTS];
// Packed coordinates of the same points in the main view
uint ElFBCoords[MAX_POINTS];
};
uniform mat4 u_lightvp;
varying vec3 v_worldpos;
void main() {
// Project the world-space point into light-space.
vec4 projected = u_lightvp * vec4(v_worldpos, 1);
// Perform perspective correction.
projected /= projected.w;
// If the point fits in the shadow multimap
if(projected.x >= -1.0 && projected.x <= 1.0 && projected.y >= -1.0 && projected.y <= 1.0 && projected.z >= -1.0 && projected.z <= 1.0) {
uint idx = atomicAdd(ElNextFree, 1);
if(idx < MAX_POINTS) {
// Insert to list
ivec2 imgCoord = ivec2((projected.xy * 0.5 + 0.5) * imageSize(u_multimap));
// Swap head of linked list with the new node
ElNexts[idx] = imageAtomicExchange(u_multimap, imgCoord, idx);
// Store the true point in projected space
ElPoints[idx] = projected.xyz;
// Pack the pixel coordinates in the main view into a 32-bit integer
ElFBCoords[idx] = (uint(gl_FragCoord.x) << 16) + uint(gl_FragCoord.y);
}
}
}Now that the multimap has been filled with points, we are now able to rasterize the scene from the light's view. While we rasterize in the sense that we utilize the fragment processor, we won't be saving our render into memory. Instead, we use it to process our multimap. Assuming we draw the scene with only triangles, what is a reasonable assumption, we can, for each pixel in the multimap, iterate through all of the points assigned to it, and compare the depths similarly to how we would with shadow mapping.
There are two subtle issues to keep in mind. Firstly, our semi-rasterization must consider every multimap pixel touched by each triangle, even if by a very small amount to ensure no false negatives. This is called conservative rasterization, and OpenGL does not support this by itself, not without either artificially adjusting the vertices of each triangle, or using extensions such as INTEL_conservative_rasterization or NV_conservative_raster, which, just to make it more interesting, aren't compatible with each other.
Even worse is already hidden above. In fact, every single article you'll find on the topic will try to smuggle this past your brains. Quoting the key paper I link above, emphasis mine:
Additionally, the fragment processor must support conditional branching and have access to the homogeneous equations describing the edges and Z interpolation [Olano and Greer 1997] of the fragment's triangle.
If you miss this sneakily hidden sentence as I did when I first read it, you'll be banging your head wondering what black magic they wield, when really it's extremely primitive, but OpenGL does not and never ever has given you such information in the fragment shader. You can't use gl_PrimitiveID or gl_VertexID with indexed rendering, nor can you use the index array for vertex attributes without the index array indexing into itself. Some pedants I'd like to name would begin lecturing about the self-contained nature of the graphics pipeline, but as a fragment is almost always a product of three vertices, having that data really isn't much to ask.
As it is unfortunately, my solution was to use geometry shaders.
In the below shader we: use the fragment coordinate gl_FragCoord to find our place in the multimap, go over every point within that multimap pixel's linked list, test if the point is truly behind the triangle we are currently rendering (given via the v_gvertex* varyings). If a point is shadowed, we must mark it as such. For this I allocated another image, where pixels in the main view are marked as 1 if shadowed, else 0.
#define MAX_POINTS (1500000)
#define BIAS 0.000001
layout(r32ui, binding = 0) uniform uimage2D u_multimap;
layout(r8ui, binding = 1) uniform uimage2D u_pixelsinshadow;
layout(std430, binding = 0) buffer Elements {
uint ElNextFree;
uint ElNexts[MAX_POINTS];
vec3 ElPoints[MAX_POINTS];
uint ElFBCoords[MAX_POINTS];
};
uniform mat4 u_lightvp;
varying vec4 v_gvertex0;
varying vec4 v_gvertex1;
varying vec4 v_gvertex2;
uniform float u_time;
// Get parametric coordinates of a triangle for point p
vec2 get_parametrics(vec2 p, vec2 v1, vec2 v2, vec2 v3) {
return vec2(
(p.x * (v3.y - v1.y) + p.y * (v1.x - v3.x) - v1.x * v3.y + v1.y * v3.x)
/ +(v1.x * (v2.y - v3.y) + v1.y * (v3.x - v2.x) + v2.x * v3.y - v2.y * v3.x),
(p.x * (v2.y - v1.y) + p.y * (v1.x - v2.x) - v1.x * v2.y + v1.y * v2.x)
/ -(v1.x * (v2.y - v3.y) + v1.y * (v3.x - v2.x) + v2.x * v3.y - v2.y * v3.x)
);
}
void main() {
uint idx = imageLoad(u_multimap, ivec2(gl_FragCoord.xy)).r;
while(idx != 0xFFFFFFFF) {
vec3 point = ElPoints[idx];
vec2 params = get_parametrics(point.xy, v_gvertex0.xy, v_gvertex1.xy, v_gvertex2.xy);
if(params.x >= 0 && params.x <= 1 && params.y >= 0 && params.y <= 1 && params.x + params.y <= 1) {
// Point is inside the triangle in 2D
// Now we must determine which of the two is closer
// Compute the Z of the triangle at the same point
float z = v_gvertex0.z + params.x * (v_gvertex1.z - v_gvertex0.z) + params.y * (v_gvertex2.z - v_gvertex0.z);
if(z + BIAS <= point.z) {
// Point is behind the triangle
// Decode the main view pixel coordinates
uint fbcoordPacked = ElFBCoords[idx];
ivec2 fbcoord = ivec2(fbcoordPacked >> 16, fbcoordPacked & uint(0xFFFF));
// Mark main view pixel as shadowed
imageAtomicExchange(u_pixelsinshadow, fbcoord, 1);
}
}
idx = ElNexts[idx];
}
}After the above shader is run, we have an image of the exact pixels in our main view that must be in shadow. If we were working with multiple lights, we would use imageAtomicOr in place of imageAtomicExchange and reserve a bit for each light.
Finally, we are able to render our scene as we normally would, but this render pass no longer needs to test shadowing, as it is all available in the image named u_pixelsinshadow above.
With this algorithm, the resolution of the multimap doesn't affect quality, but it does affect performance, and a resolution of 1x1 obviously isn't most performant.
It goes without saying that these shaders are very expensive. The main paper goes much further into optimization, such as exiting early using the stencil mask. They also use a small multimap size while hashing point coordinates to equalize the number of points at each multimap cell.
But the worst offender by far is the geometry shader. If you enable the geometry shader stage, every triangle you draw will now have unique vertices, even if they were shared by triangles before, which leads to performance and memory issues. It does not take much for my system to begin OOMing and for fonts to actually become corrupt in my window environment. If indexed rendering is ditched, and hardware-based conservative rasterization is used, then performance should dramatically improve, but that requires succumbing to the idiocy of INTEL_conservative_rasterization being core-only, and the enforcement of such rartedly arbitrary limitations at the driver level (thanks again, Mesa).

Bye.